👁 Anotacion tipos celulares
Anotación de tipos celulares
BIENVENIDOS
Presenta: Erick Cuevas Fernández




![]()

Anclas con Seurat
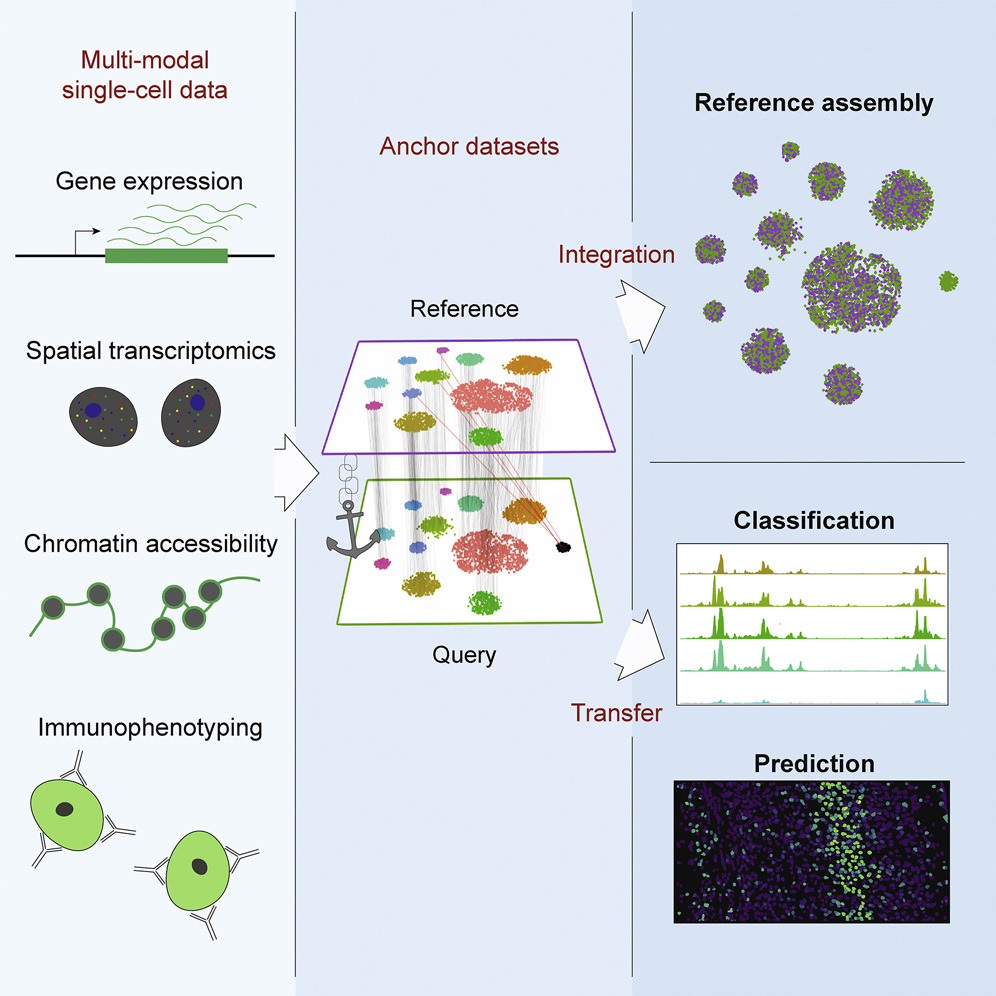
El problema con el que trabajaremos
Conjunto de datos a trabajar
La mejor estrategia para anotar, es entender el problema.

Observar calidad de predicción
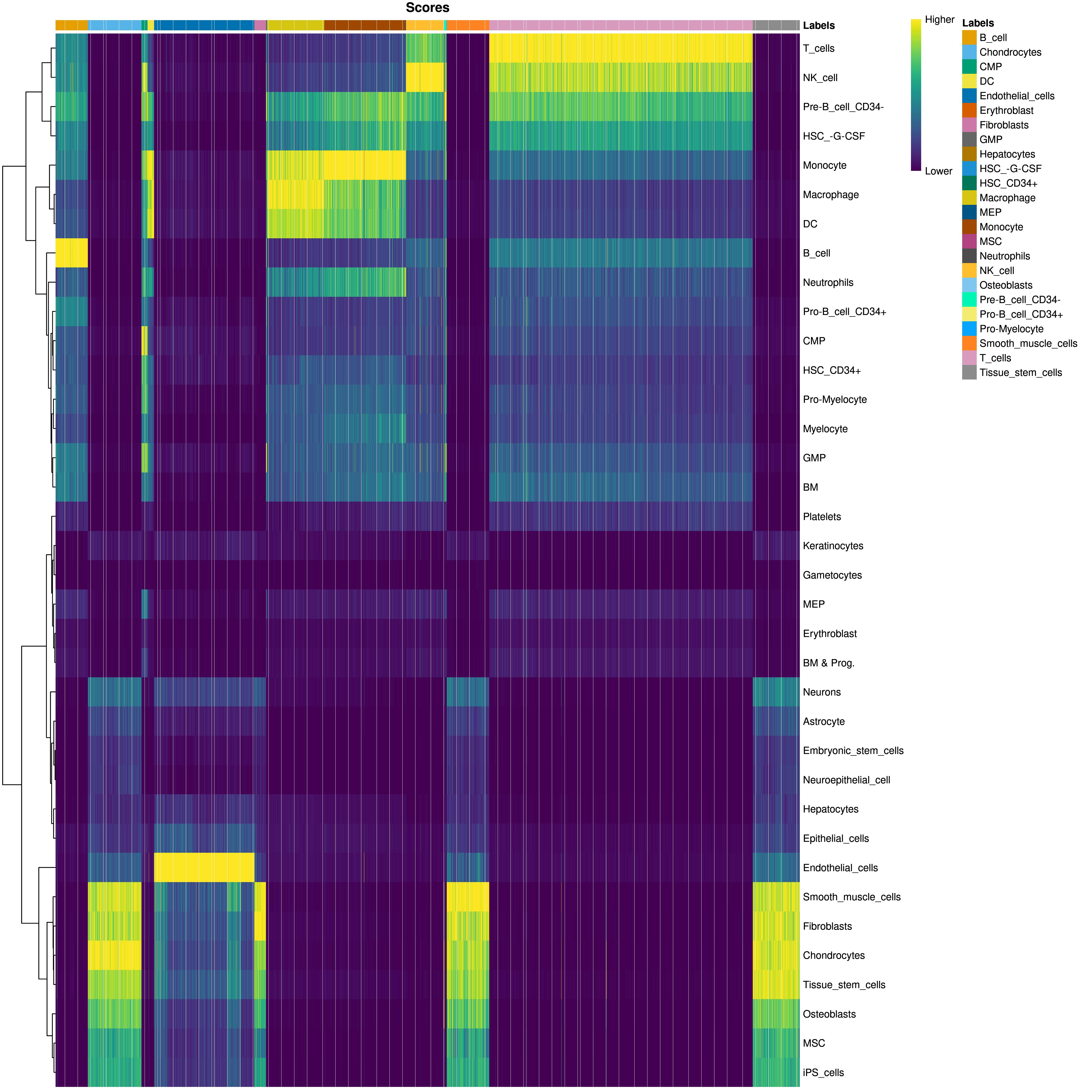
summary(is.na(pred$pruned.labels))
# Grafico para ver las celulas eliminadas
# plotDeltaDistribution(pred.grun, ncol = 3)
to.remove <- is.na(pred$pruned.labels)
table(Label=pred$labels, Removed=to.remove)
to.remove <- pruneScores(pred, min.diff.med=0.2)
table(Label=pred$labels, Removed=to.remove)
# Modificamos nuestro sce
sce_dummy <- sce[,to.remove]
sce_dummy$new_labels <- pred$labels[to.remove]
table(sce_dummy$new_labels)
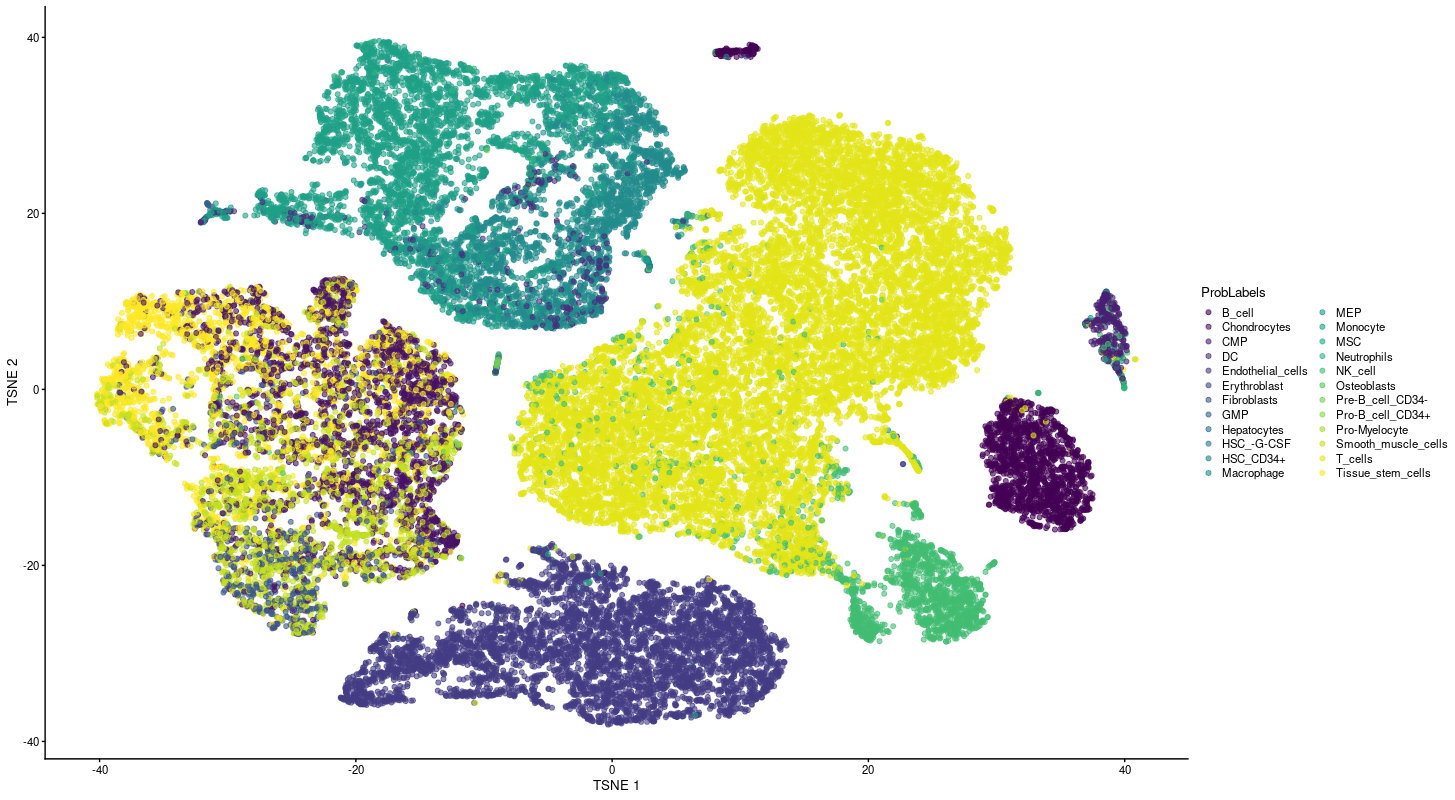
plotReducedDim(sce_dummy, "TSNE", colour_by="new_labels")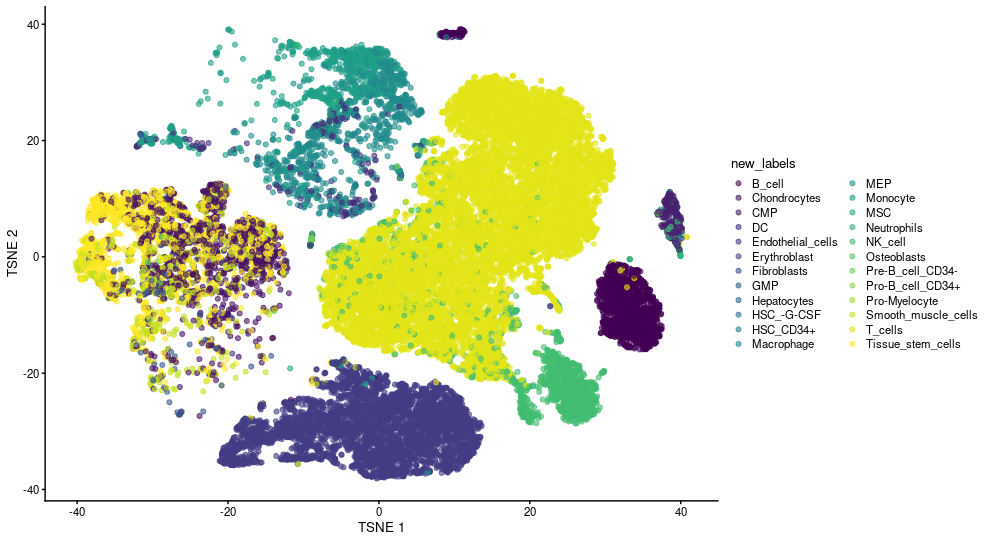
Aproximación “artesanal”
¿Qué hacemos si nuestra anotación aún no es la “ideal”?

Ahora se ven asi nuestro clusters
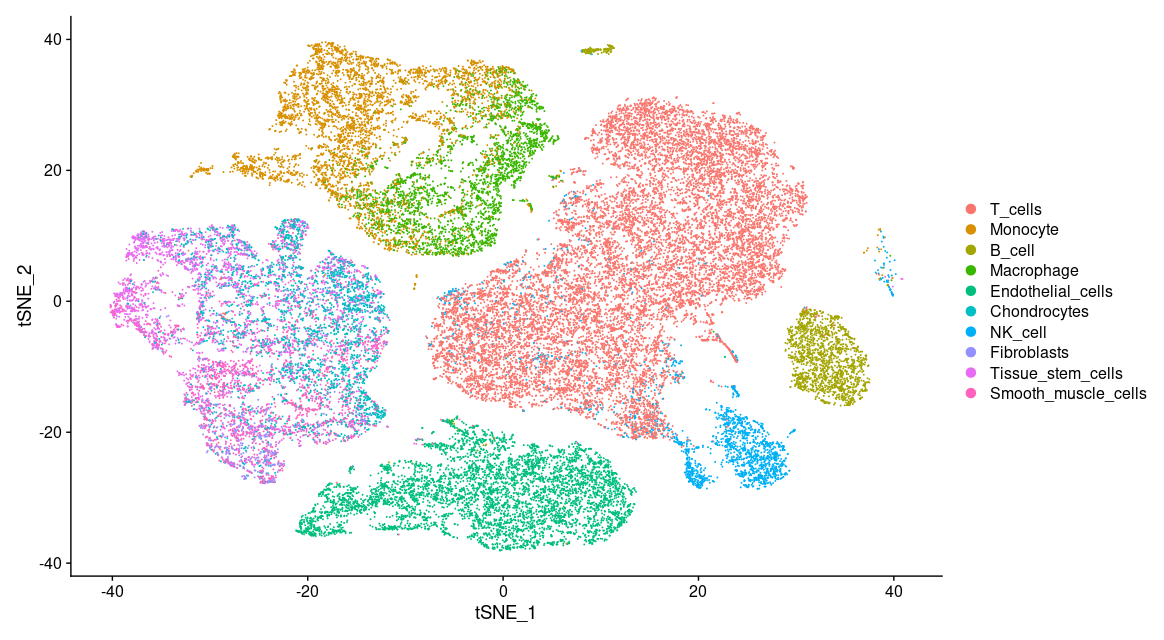
¿Y si quiero agregar un tipo celular basado en genes marcadores?

Observamos la expresion en conjunto
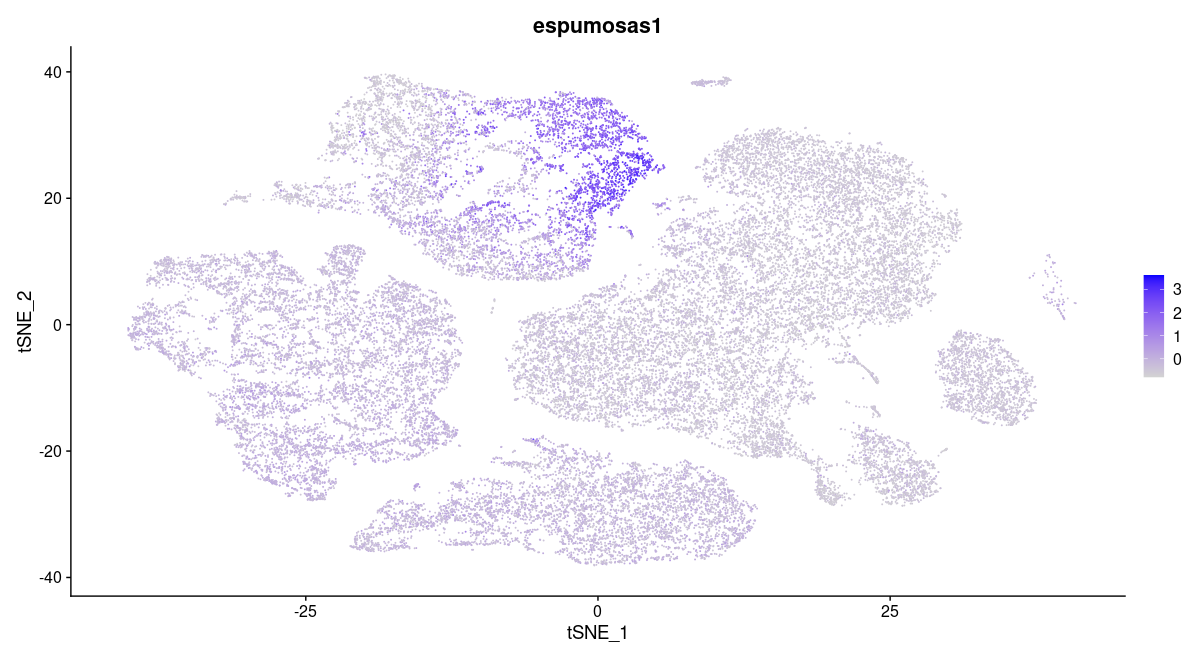
tSNE
UMAP
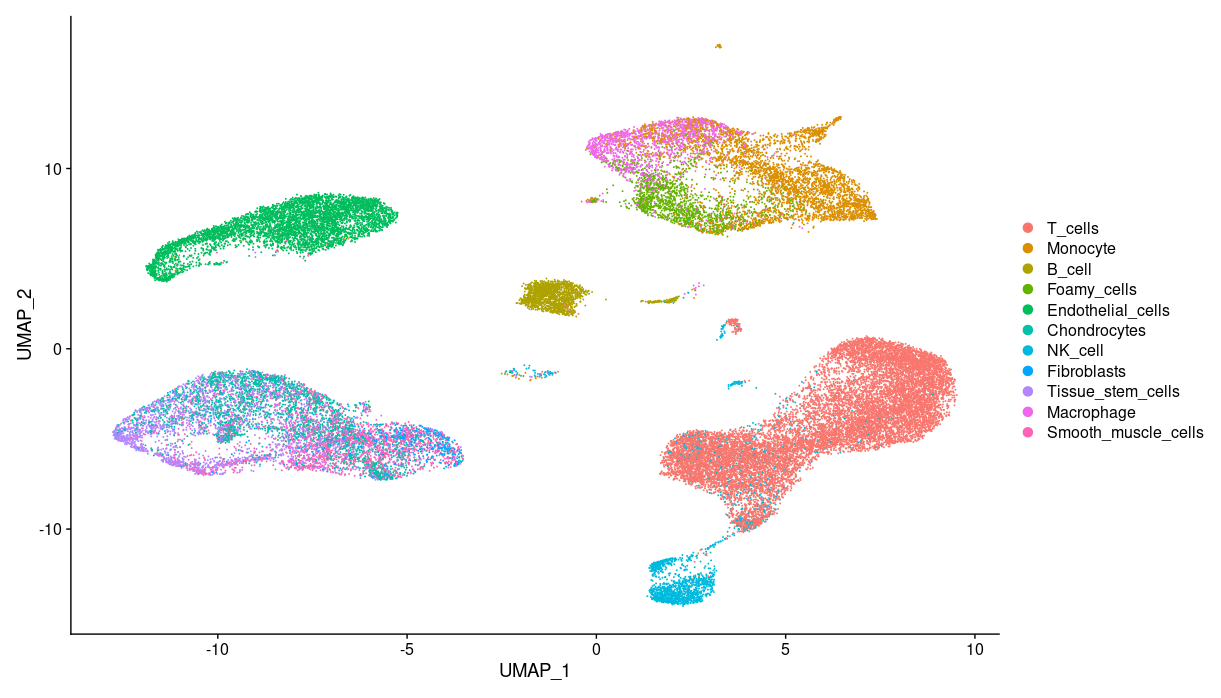
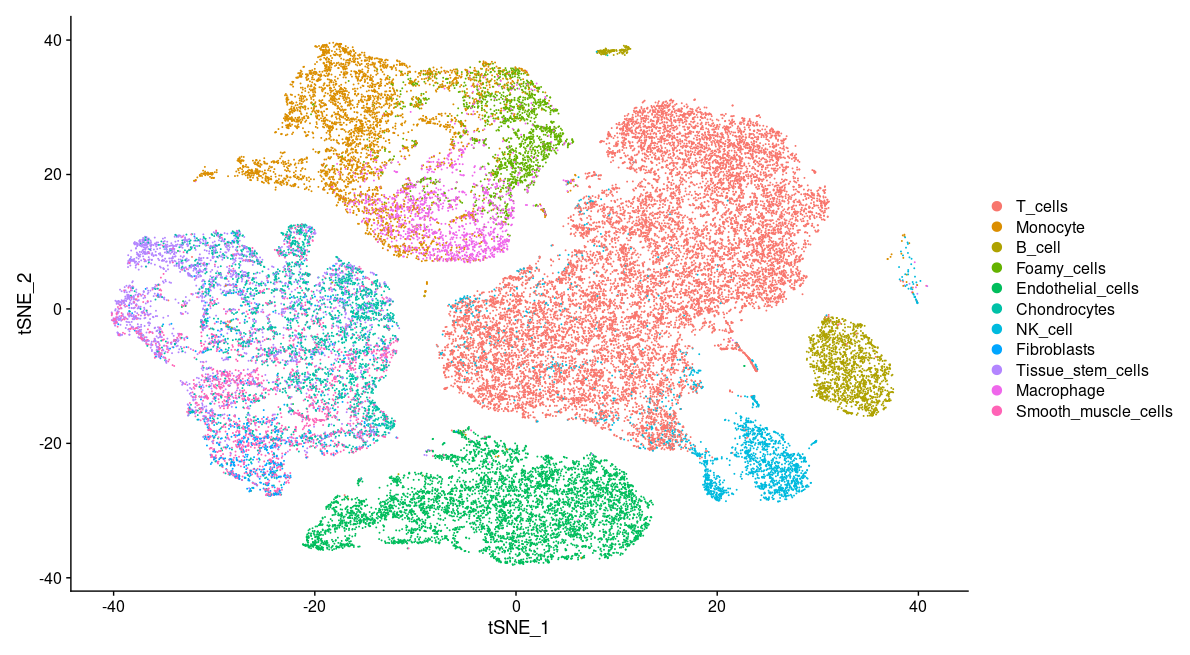
¿Tiene sentido?
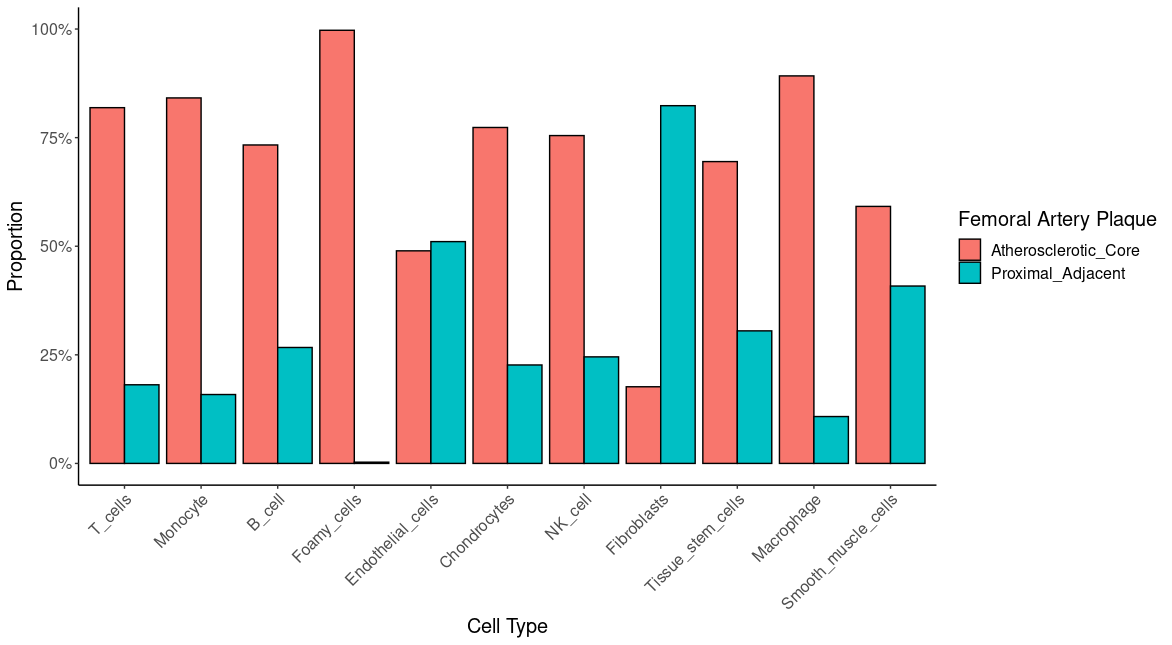
¿Tiene sentido?
El fin
MUCHAS GRACIAS
